Summary of the context and overall objectives of the project
Is a hot rolling mill secured against intentional attacks? Could a re-heating furnace or accelerated cooling be used to sabotage the quality of a European steel producer? How can attacks be separated from fault behaviour? AutoSurveillance will provide a solution for detecting anomalies in re-heating furnaces, hot-rolling mills and accelerated cooling, a solution that can announce a threat and distinguish between faults and intentional attacks in parallel. It focuses on the process-oriented treatment of such occurrences rather than the IT perspective. AutoSurveillance has proposed three different “in-deep“ views, ranging from control components in a plant, plant level, and facility level, where time frameworks for detection and reaction are consistently different.
First, the definition of faults and attacks and their interplay with model uncertainties and disturbance was discussed. And how these can be distinguished in principle from a set-theoretical point of view. And how, from a set-theoretical point of view, these are, in principle, distinguishable. Subsequently, plant-specific details were discussed. Accordingly, a risk assessment of the faults considered, and their financial impact was attempted for each use case. The plant’s physical /and data-driven models and controls were set up according to this. These models have been extended to include actuator, sensor, and parameter faults models. In addition, models for Denial of Service (DoS) and Hidden Attacks have been added. For example, it was possible to show that a DoS attack on the control of the hot strip lines leads to a destabilisation of the control and, thus, to a strip break. It is possible to adjust the strip thickness unnoticed using a hidden attack. Different methods of detecting faults and attacks were investigated.
On the one hand, model-based approaches such as different observer concepts (Kalman filter, extended Kalman filter and banks of Kalman filter) whose results were evaluated using a One-Class Support Vector machine to distinguish the root cause of the faults and attacks. Using the Support Vector machine also ensures the robustness of the decision-making against disturbances and uncertainties. On the other hand, data-driven methods were investigated. Here, the focus was non-linear mapping to low dimension and machine learning methods based on auto-encoders. With each of these methods, it was possible to detect faults and attacks and to determine the root cause of the faults and attacks.
Attack techniques that focus on stealth and redundant access make them challenging to detect and stop. Intrusion detection systems monitor networks and alert security authorities to potential intruders, but many alerts go unanswered due to high false alarm rates. Similarly, in fault detection, the possible response to faults depends on fault detection and isolation reliability. Based on these considerations, we propose a three-step approach. First, the user is alerted. This is always activated as soon as an anomaly is detected. Second, suppose it is possible to determine the type of fault or attack (e.g., isolation) and depending on the accuracy and impact of the fault and attack, a manual countermeasure is taken, i.e. in that case, a human reacts, or third, an automatic countermeasure is taken to move the system into a safe area.
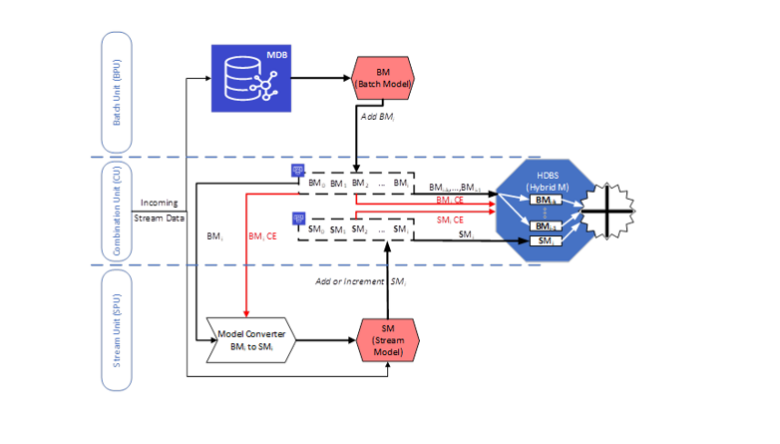
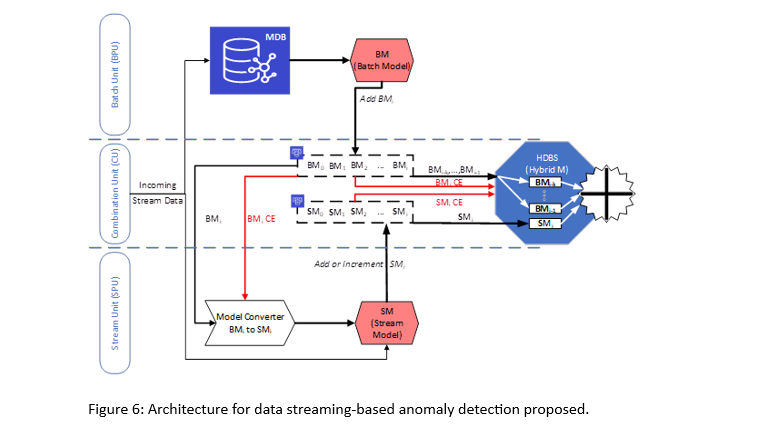
We introduce a Hybrid Distributed Batch-Stream (HDBS) architecture explicitly designed for real-time data anomaly detection. The hybrid architecture combines the accuracy of batch processing with the speed and real-time capabilities of stream processing. In our proposed architecture, we specifically emphasise the algorithmic aspects of hybrid processing, including the characteristics of machine learning algorithms and the principles of integrating results from different processing units.
The automatic reaction strategies for DoS-Attack were demonstrated for a single control loop, the looper and the thickness controller of a finishing mill. Hardware in the loop simulation for faults and attack detection was carried out for reheating furnaces and accelerated cooling lines at the Prisma facility. Finally, data-driven methods were demonstrated for a whole production line at one of Sidenor’s long product lines.
For full utilisation of the project’s solutions, staff at SIDENOR and PRISMA is trained to operate the developed software modules and to integrate them further into other areas of their businesses. The staff training focuses on the developed applications‘ uses, transferability, adaptability, and dissemination.
Ten publications have been made on this project, including one conference workshop.
Work performed and main results achieved
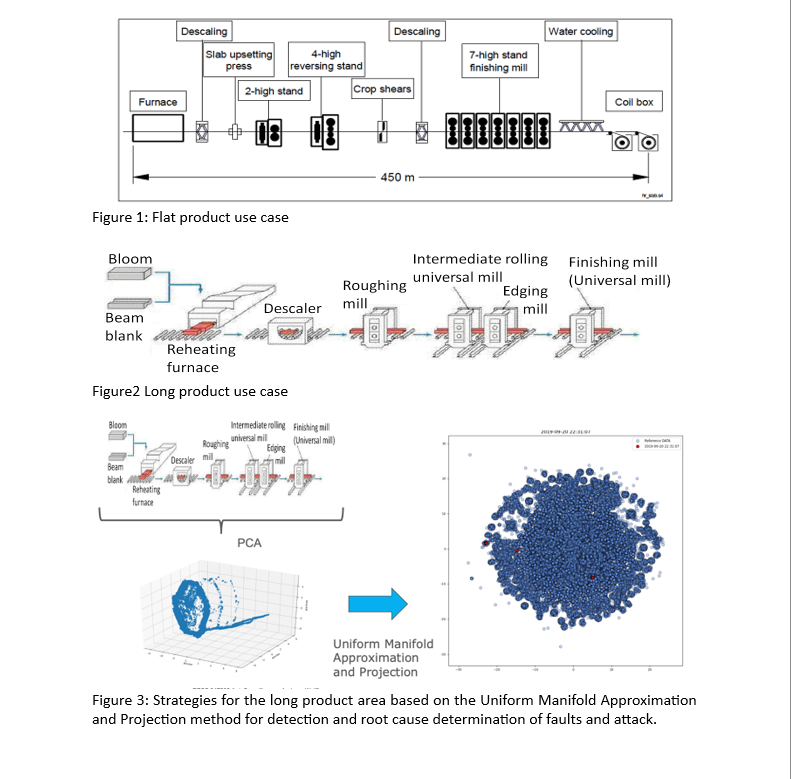
At the beginning of the project, the AutoSurveillance consortium developed an abstract definition of faults and attacks compared to model uncertainties and disturbances. In the next step, a risk assessment was performed. Different analysis methods were compared and evaluated for the three use cases: reheater and advanced cooling, hot rolling mill for flat products (see Figure 1) and hot rolling mill for long products (see Figure 2)
In the three use cases, we focused on different aspects. We covered the examination of controllers in a plant, on the plant level and up to the facility level.
- At Plant Level: We concentrated on a looper and thickness control in the use case finishing mill and analysed it in detail.
- On Plant Level: In the use case of the reheating furnace and rapid cooling, we investigated the automation of the entire plant.
- Facility Level: Process In the use case of plant products, we investigated methods suitable for the entire process chain.
Fault and Attacks
The faults can be classified as follows:
- Plant Faults: Such faults change the dynamical I/O properties of the system.
- Sensor faults: The plant properties are unaffected, but the sensor readings have substantial errors.
- Actuator faults: The plant properties are unaffected, but the controller’s influence on the plant is interrupted or modified.
Furthermore, the faults can be divided into the following types:
- Stepwise change of actuator or sensors values.
- Slowly varying actuator or sensor values
- Stepwise change of process parameter
- Process faults like drifting or creeping
In this project, we focus on the following attacks:
- Denial-of-service (DoS) attack: A denial-of-service attack occurs when legitimate users are unable to access information systems, devices, or other network resources due to the actions of a malicious cyber threat actor. A denial-of-service condition is accomplished by flooding the targeted host or network with traffic until the target cannot respond or crashes, preventing access for legitimate users. DoS attacks can cost an organisation time and money while its resources and services are inaccessible.
- Man-in-the-middle attacks: The attacker stands either physically or – today mostly – logically between the two communication partners, has complete control of the system over the data traffic between two or more network participants and can view and even manipulate the information at will. This attack’s danger lies in the fact that the attacker pretends to be the respective counterpart to the communication partners.
- Bias injection: Incorrect data is added to an actuator or sensor, causing the process to malfunction,
- Covert attack: Incorrect data is added to an actuator or sensor, causing the process to malfunction without the operator or monitoring system noticing.
Cyber-attacks can cause these attacks. A cyber-attack is a targeted attack on one or more information technology systems to impair the IT and OT systems entirely or partially by information technology means. This way, the attacker can access and change the process control system. The attack takes place exclusively in virtual cyberspace.
Fault and Attack detection and isolation
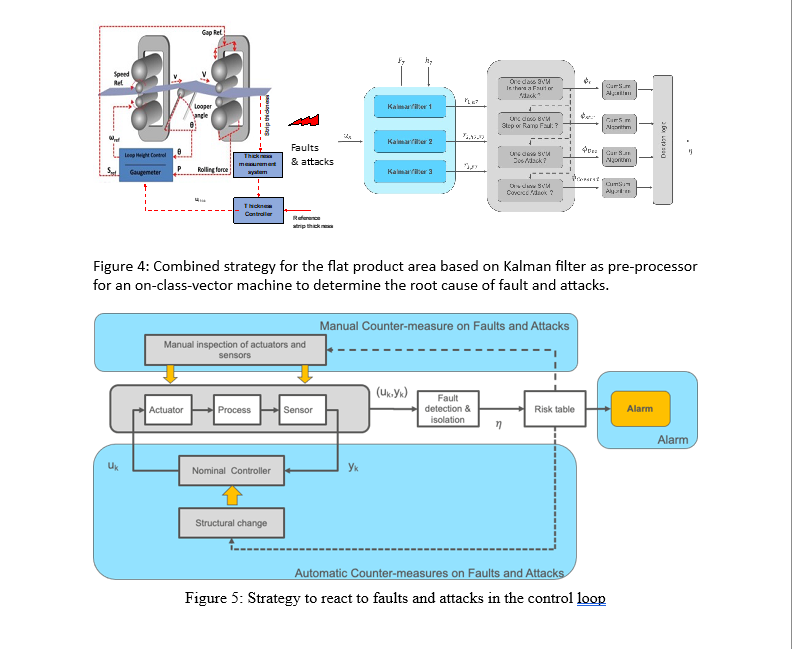
Driven by the industrial partners of the consortium, an estimation of the costs that faults and attacks might originate was created. Several physical and data-driven models were developed based on defined attacks and faults for the three use cases. The physical models were based on observer strategies; the data-driven techniques were based on projection methods into lower dimensional spaces (see Figure 3), and the ML approach was based on an autoencoder. The combined strategy uses the observer-based approach to pre-process the subsequent cause determination using the one-class support vector machine for the fault or attack, see Figure 4.
Reaction strategies
Attack techniques focusing on stealth and redundant access make them challenging to detect and stop. Intrusion detection systems monitor networks and alert security agencies to potential intruders, but many alerts receive no security response due to the high false alarm rate.
Similarly, when it comes to fault detection, the possible response to faults depends on the reliability of fault detection and isolation. Considering the expected conditions and capabilities on site in the factories, a three-stage concept was developed to respond to the identified anomalies. The first stage is an alarm that will always be triggered as an immediate response. Then, based on the available information, one of the two other stages will be applied. The next stage, a manual countermeasure, will have a human react to the anomaly. As the third stage, an automatic countermeasure will bring the system to a safe state for further examination if necessary.
Figure 5 shows the structure of the response to faults and attacks. After a fault or attack has been detected and isolated, a reaction strategy is triggered via a risk evaluation table. Three types of reactions are triggered:
- Alarm: Rise alarm to the user. This is always activated as soon as an anomaly is detected.
If it is possible to determine the type of fault or attack (e.g., isolation) and depending on the accuracy and impact of the fault and attack,
- a manual countermeasure is taken, i.e. a human reacts or
- an automatic countermeasure is taken to move the system into a safe area,
The manual countermeasures strategy was implemented for reheating furnaces and Accelerated cooling. In the simulation, we test an automatic counter measurement on a DoS attack of the thickness measurement system of a finishing mill.
IoT / Streaming architecture
Effective anomaly detection relies on both recent and historical data. Therefore, a balance between speed and accuracy is needed. We introduce a Hybrid Distributed Batch-Stream (HDBS) architecture designed to achieve the desired real-time data anomaly detection results, see Figure 6. The hybrid architecture combines the accuracy of batch processing with the speed and real-time capabilities of stream processing. In our proposed architecture, we specifically emphasise the algorithmic aspects of hybrid processing, including the characteristics of machine learning algorithms and the principles of integrating results from different processing units. Such a structure makes total sense because of the designed scope of the analysis, where the other use cases have a different exploratory perspective (component level for case I, „Hot strip mill, looper and thickness control“, production line for case II „hot strip mill: reheating furnace and accelerated cooling“ and system level (something in the middle of the other two cases) for case III „Whole productions line for long products“). Therefore, for case I, the design needs to be pure streaming, whereas for the second, since the ambition is monitoring, the scale is a hybrid between batch and streaming.
When detecting anomalies requires a balance between speed and accuracy, relying solely on either stream processing or batch processing paradigms fails to yield satisfactory outcomes. This is because effective anomaly detection relies on both recent and historical data and becomes clear from the lab work carried out and because of the different scopes adopted. In such scenarios, a viable solution to achieve the desired results is to employ hybrid processing, which combines the strengths of both batch and stream processing approaches. Therefore, the proposed architecture can use big data infrastructures in batch and stream processing units and identify anomalies with high speed and accuracy.
Figure 6 illustrates the processing infrastructure of the Hybrid Distributed Batch-Stream (HDBS) system, drawing inspiration from the Lambda architecture. It comprises three distinct units: the batch processing unit (BPU), the stream processing unit (SPU), and the combination unit (CU).
The first processing unit of the HDBS is Batch Processing Unit (BPU). The main task of this unit is to create accurate models from a large amount of incoming training stream data. This unit’s primary purpose is to increase anomaly detection accuracy. Since the training data is streamed in the system, the batch processing unit should have a master database (MDB) for storing incoming training data. Different solutions have been tested, and InfluxDB alternative suits very well for this purpose.
In addition to the MDB, the unit incorporates a component dedicated to constructing batch models as an offline detector. This component leverages the data stored in the MDB to build precise batch models over time. Each model uses a specific period of recent data available in the MDB. Once a model is created, a new model is generated using the next period of current data, which may include a combination of new and existing data within the MDB. This iterative and periodic process ensures the continuous reconstruction of models by the component.
The stream processing unit (SPU) is the second parallel processing unit in the HDBS architecture, operating alongside the batch processing unit (BPU). Its primary function is to handle the continuous data flow by utilising a portion of newly arrived data. The learning model employed by the SPU is designed to be incremental, gradually becoming more comprehensive as time progresses. This unit promptly reports its processing outcomes in real-time, primarily aimed at enhancing the response time for anomaly detection. Unlike the batch processing unit, the stream processing unit does not store the incoming stream data.
The third unit within the HDBS architecture is the combination unit (CU). Its primary function is to facilitate the rapid loading of processing models generated by the batch processing unit (BPU) and the stream processing unit (SPU) and subsequently merge them. This merging process is essential for achieving a fast and efficient combination of models, as implemented in the proposed hybrid algorithm (HDT). To fulfil its role effectively, the combination unit is equipped with databases that enable swift data retrieval and access. Consequently, the batch processing unit and the stream processing unit store their respective models, represented as trees or other appropriate structures, in dedicated databases designed for batch and stream models. The combination unit then presents these stored models to the merging component (MC), utilising the fast databases. The merging feature is responsible for merging the processing models to create the final hybrid detector.
The cloud-oriented architecture will be analysed to facilitate transferability while maintaining the solution’s reliance and resilience attributes, including Apache Kafka producer-broker-consumer architecture and server-less microservice container-oriented architectures.
Overview of the results and their exploitation and dissemination
The RFCS project AutoSurveillance has implemented a framework for fault and attack detection, isolation, and reaction strategies. The applicability of this framework was demonstrated in three use cases ranging from single control loops to a plant and finally to a production chain.
A Hardware-In-the-Loop (HIL) application has been designed and developed during the AutoSurveillance project for the case studies related to the reheating furnace and the accelerated cooling lines. The HIL application makes it possible to simulate in detail the processes‘ dynamic behaviour during normal and abnormal operations and assess the control system’s robustness to anomalies and cyber-attacks. In addition, a software solution provides a graphical user interface for monitoring users to evaluate the current operation of the processes and to use anomaly detection algorithms helpful in guiding the monitoring task. Both applications form the basis for developing and testing future algorithms and control systems for industrial use. Furthermore, the applications can be continuously improved and transferred to additional use cases.
The automatic reaction strategies for DoS-Attack were demonstrated for a single control loop, the looper and the thickness controller of a finishing mill. Hardware in the loop simulation for faults and attack detection was carried out for reheating furnaces and accelerated cooling lines at the Prisma facility. Finally, data-driven methods were demonstrated for a whole production line at one of Sidenor’s long product lines.
For full utilisation of the project’s solutions, staff at SIDENOR and PRISMA is trained to operate the developed software modules and to integrate them further into other areas of their businesses.
The staff training focuses on the developed applications‘ uses, transferability, adaptability, and dissemination.
Additionally, the consortium conducted several dissemination activities at international conferences and in international journals, as the following list demonstrates.
- Neuer, M., Kretschmer M., Wolff A., “Automation security in the era of Industry 4.0”, Future Steel Forum, September 2019, Budapest
- Neuer M., Wolff A, Holzknecht N., “Cyber-attacks for breakdown or intentional quality reduction – how secure is the European steel production in the era of digitalization?”, Conference: European Steel Technology and Application Days (METEC & 4th ESTAD) June 2019
- Wolff , Neuer M, Holzknecht N., Deprez J.Ch., Monton St., Colla V, Iannino V., Bottazzi C. Ferraris F., Ordieres-Mere J., Arteaga A., “Automatic surveillance of hot rolling area against intentional attacks and faults (AutoSurveillance). Overview and first results of the RFCS-funded Project”, ESTAD 2021 Stockholm
- Ordieres-Meré J, Arteaga A., Matskanis N., Wolff A., Iannino V., “Process Supervision of Long Products Hot Rolling Mill. Attack or Failure Identification”, IFAC-PapersOnLine 55(2):72-77, January 2022
- Ordieres-Mere J., Wolff A., Pacios-Alvarez A., “Cybersecurity challenges in downstream steel production processes”, 1st IFAC Workshop on Control of Complex System Cosy 2022: Bologna, Italy, 24-25 November 2022
- Ordieres-Mere J., Wolff A., Bello-García A., Dettori St., “Contributions from cloud-based OT solutions for downstream steel processes”, ESTAD 2023, Düsseldorf
- Wolff A., Neuer M, Holzknecht N., Deprez J.Ch., Monton St., Colla V, Dettori St., Bottazzi C. Ferraris F., Ordieres-Mere J., Arteaga A., “Reliable digital twins for the transition to a CO2-free steel industry” ESTAD 2023, Düsseldorf
- Liu, Q. Zeng, J. Ordieres Meré, H. Yang, “Anticipating Stock Market of the Renowned Companies: A Knowledge Graph Approach”, Complexity, 2019
- Villalba-Diez J., Ordieres-Meré J., González-Marcos A., Soto Larzabal A., “Quantum Deep Learning for Steel Industry Computer Vision Quality Control.”, IFAC-PapersOnLine, Volume 55, Issue 2, 2022, Pages 337-342
- Ordieres-Meré J., Gutierrez M., Villalba-Díez J., “Toward the industry 5.0 paradigm: Increasing value creation through the robust integration of humans and machines“, Computers in Industry, Volume 150, September 2023
Additionally, a workshop was organised by the partners BFI and SSSA. This workshop elucidates the steel industry concerning the dangers of attacks on automation systems. It had to be clarified why solid fault detection a mandatory element of any attack prevention approach is and how to establish attack detection and mitigation on the existing computational infrastructure of the plants.
The following workshop was held at Word CIST 2023 on April 4-6, Pisa, Italy:
- 1st Workshop on Information Systems and Technologies for the Steel Sector.
Progress beyond the state of the art and potential impacts
The main progress beyond the state of the art was reached by defining fault and attack types using a unified framework. Methods for detecting faults and attacks tailored to steel production processes were developed. Observer-based methods, data-driven methods for the projection into lower dimensional spaces, and ML methods for non-linear dimension reduction were used.
The development and enhancement of European technological, strategic, and digital autonomy must go through the development and enhancement of the industrial and technological European cybersecurity, facilitating synergies between EU industry and the EU academic, furthermore reducing the dependence on non-EU technology.
The threat of cyberattacks against industrial plants is real, and their frequency constantly increases. The comprehensive protection of industrial plants against internal and external cyberattacks requires an approach that covers all levels simultaneously – from the operational to the field level.
The technical and economic potential to use the results of the AutoSurveillance project are:
- Reduces risks and impacts on the plant/process/production in case of attack; after the mitigation actions of the risk response planned and described in the Deliverable D1.2
- Reduces costs derived by damages on the plant/process/production in case of attack.
- Reduces costs derived by loss of know-how and confidential information.
- Increase the operational technology safety in the industrial plants through the reaction strategies planned.
- Increase the operational technology safety in the industrial plants by training the planned plants‘ engineers and operators.
- The transferability and adaptability of the AutoSurveillance system described ensure that the AutoSurveillance system can be installed and used in other companies and plants.
The technologies, hardware and software used for engineering and developing the software prototype of the AutoSurveillance system are the most modern and safe currently usable and purchased on the European market; the engineered and acquired technologies,
Images are attached to the Summary for publication.
Acknowledgement
This project receives funding from the Research Fund for Coal and Steel under the Grant Agreement Number 847202.